É importante entender o papel do viés da IA na saúde. À medida que os aplicativos de inteligência artificial (IA) ganham força na medicina, os líderes de saúde que sempre buscam esclarecer para que serve Nervamin entre outros medicamentos, expressaram preocupação com os efeitos indesejados da IA no preconceito social e na desigualdade. O software de inteligência artificial (AI) pode ajudar a analisar grandes quantidades de dados para melhorar a tomada de decisão.
Cada vez mais, passamos a contar com esses algoritmos para diferentes tipos de propósitos como saber para que serve Simeticona . É, portanto, essencial que seus resultados sejam confiáveis. Infelizmente, nem sempre é esse o caso. Existem muitos exemplos de resultados errôneos de algoritmos de IA que são, mais frequentemente do que gostaríamos, causados por vieses. Até mesmo grandes empresas, como a Amazon, acabam usando algoritmos tendenciosos de vez em quando.
Em 2015, a Amazon tentou treinar um algoritmo para classificar os candidatos adequados para as vagas de emprego com base em seleções anteriores. O resultado? Um algoritmo que atribui altas classificações a candidatos do sexo masculino, porque eles foram selecionados com mais frequência no passado, e classificações mais baixas a candidatos com um perfil “menos familiar”, como as mulheres. O algoritmo foi treinado em dados tendenciosos, portanto, resultados tendenciosos eram esperados.
Embora os algoritmos tendenciosos devam sempre ser evitados, pois não informam com clareza para que serve Simeticona há circunstâncias em que isso é nada menos que crucial, como a saúde. No entanto, nem sempre é perfeitamente claro quando um algoritmo é tendencioso e quando não é. Para desenvolver uma melhor compreensão dos riscos que os algoritmos enviesados trazem para a saúde, explicaremos o fenômeno do enviesamento com mais detalhes e discutiremos alguns exemplos.
O que exatamente é o viés da IA na área da saúde e por que é importante lidar com isso?
O preconceito é mais complicado do que a maioria das pessoas pensa. Sim, o viés em um algoritmo é ruim, mas quando exatamente um algoritmo é tendencioso? Muitas vezes é descrito como uma tendência ou tendência particular em um algoritmo de retornar uma determinada resposta, mas e se você estiver desenvolvendo um algoritmo que supostamente classifica tumores cerebrais e favorece fortemente a resposta “não maligno” em vez de “maligno”?
Isso provavelmente se deve ao fato de que, estatisticamente, os tumores cerebrais não malignos são mais prevalentes do que os malignos.2 Portanto, se você usou um conjunto de dados representativo para o treinamento do algoritmo, deve se preocupar se o algoritmo não favorece os não malignos. Isso não é preconceito.
É algo que pretendemos alcançar. Só o chamamos de viés se o algoritmo for inclinado para uma resposta considerada errática. Portanto, se o seu algoritmo tem maior probabilidade de classificar um tumor cerebral como não maligno enquanto você o usa para um grupo de pacientes para o qual sabe que eles têm maior probabilidade de ter um tumor cerebral maligno, então você está lidando com um viés. Esteja ciente de que isso significa que um algoritmo será tendencioso, dependendo de como ele é treinado e como é aplicado.
Para entender melhor essa diferença entre um algoritmo que faz o que deve fazer e um algoritmo que é tendencioso, discutiremos 3 exemplos de viés em um contexto clínico.
Viés de IA no exemplo 1 de saúde: detecção precoce de Alzheimer usando dados de fala
Há algum tempo, uma empresa canadense chamada Winterlight Labs desenvolveu testes informando para que serve Sinvastatina. O software deles registra a maneira como você fala, analisa os dados e diz se você pode ter doença de Alzheimer em estágio inicial. No entanto, os desenvolvedores usaram um conjunto de dados de treinamento contendo amostras de fala apenas de falantes nativos de inglês.
Como resultado, o algoritmo pode interpretar pausas e diferenças nas pronúncias entre falantes não nativos de inglês como marcadores de uma doença.
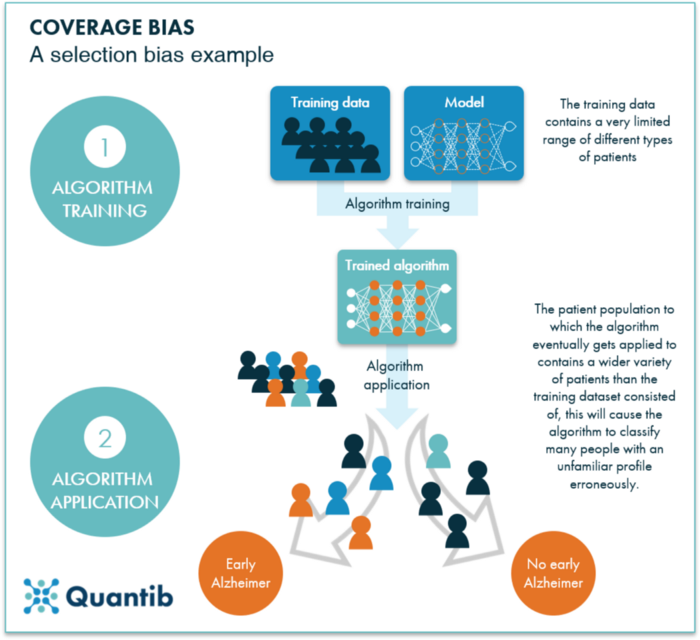
Figura 1: Um exemplo de viés de cobertura: o algoritmo é treinado em um conjunto de dados contendo um tipo específico de pacientes, e a aplicação do algoritmo resultante a outros tipos de pacientes pode resultar em resultados errôneos. O algoritmo não foi capaz de aprender os detalhes de uma ampla gama de tipos de pacientes.
O que podemos aprender com este exemplo de viés de IA na saúde?
Esse tipo de viés é chamado de viés de cobertura, que é um subtipo de vieses de seleção.4 Ao treinar um algoritmo de IA, é extremamente importante usar um conjunto de dados de treinamento com casos representativos dos casos aos quais o algoritmo treinado será aplicado.
Na área da saúde, isso geralmente se resume a ter seu conjunto de dados de treinamento contendo assuntos que são representativos da população de pacientes do hospital onde o algoritmo será usado. Usar um conjunto de treinamento com uma distribuição de tipos de pacientes muito diferente da população a ser analisada resultará em um viés de seleção. Por outro lado, esse tipo de viés está diretamente relacionado à observação “depende de como é aplicado” feita anteriormente.
Se você planeja usar seu algoritmo em uma população exclusivamente masculina, não há mal nenhum em treinar o algoritmo com dados de homens. Apenas um exemplo maluco: se você quiser detectar o câncer de próstata, não vai incluir tomografias da região pélvica feminina, vai? Apenas certifique-se de que os dados de treinamento correspondem, até certo ponto, aos dados nos quais você eventualmente aplicará o algoritmo.
Viés de IA no exemplo 2 de saúde: diagnosticar câncer de pele em diferentes tipos de pele
Além de o conjunto de treinamento ser representativo da população, é importante que o conjunto de treinamento seja equilibrado. Um estudo da Universidade de Stanford afirmou que um sistema de IA teve um desempenho comparável ao de um dermatologista treinado ao diagnosticar lesões cutâneas malignas por imagens.
O conjunto de dados que os pesquisadores usaram, no entanto, consistia principalmente em amostras de pele caucasiana. Pessoas brancas sofrem de câncer de pele com mais frequência, então simplesmente havia mais dados disponíveis para esse tipo de pele.
Mesmo que um algoritmo treinado com esses dados tenha mais probabilidade de diagnosticar pessoas com pele clara, ele ainda precisa aprender sobre outros tipos de pele também. Caso contrário, o algoritmo de IA tenderá para uma pele mais clara e não é adequado para uso clínico em um hospital com uma população de pacientes com uma ampla variedade de tipos de pele.
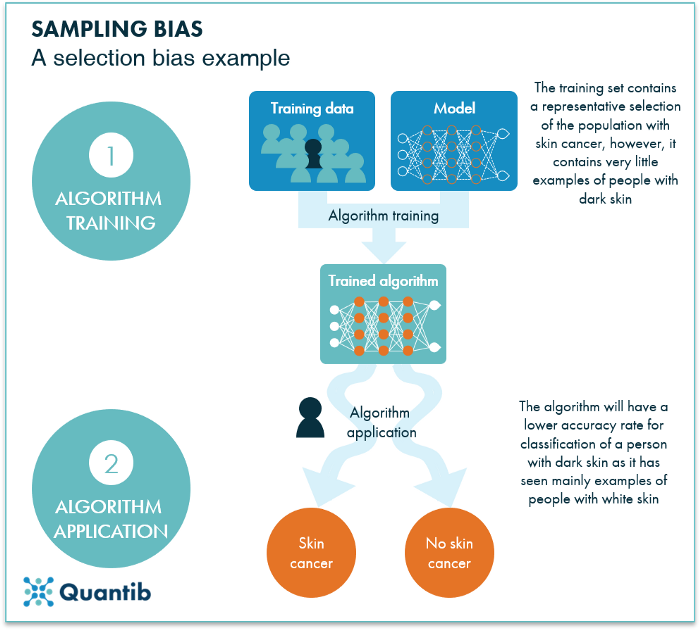
Figura 2: Um exemplo de viés de amostragem: o algoritmo foi treinado em um conjunto de dados de paciente contendo uma quantidade muito pequena de um determinado tipo de paciente. O algoritmo resultante terá grande dificuldade em classificar os casos desse tipo específico de paciente, pois nunca teve a chance de aprender as especificidades desse grupo.
O que podemos aprender com este exemplo de viés de IA na saúde?
Não é suficiente apenas ter um conjunto de dados representativo da população de pacientes à qual você planeja aplicar seu algoritmo. Você precisa ter certeza de que as minorias em sua população de pacientes também estão bem representadas em seu conjunto de dados. Este também é um exemplo de viés de seleção. Para ser mais preciso, chamamos esse tipo de viés de viés de amostragem.4
Viés de IA no exemplo 3 de saúde: previsão do tempo de internação
Em outro caso, um algoritmo foi desenvolvido para prever o tempo de internação hospitalar para identificar os pacientes com maior probabilidade de receber alta precoce e para que serve Trinulox. O algoritmo usou dados clínicos para chegar a uma recomendação, e os pacientes que provavelmente teriam alta mais cedo teriam um gerente de caso designado.
No entanto, adicionar o código postal aos dados de treinamento melhorou fortemente a precisão do algoritmo. Descobriu-se que os pacientes que moravam em bairros mais pobres eram mais propensos a ter um tempo de internação mais longo. Se este plano tivesse sido posto em prática, os gerentes de caso teriam sido designados para pessoas mais ricas, enquanto os menos privilegiados poderiam realmente ter usado a ajuda.
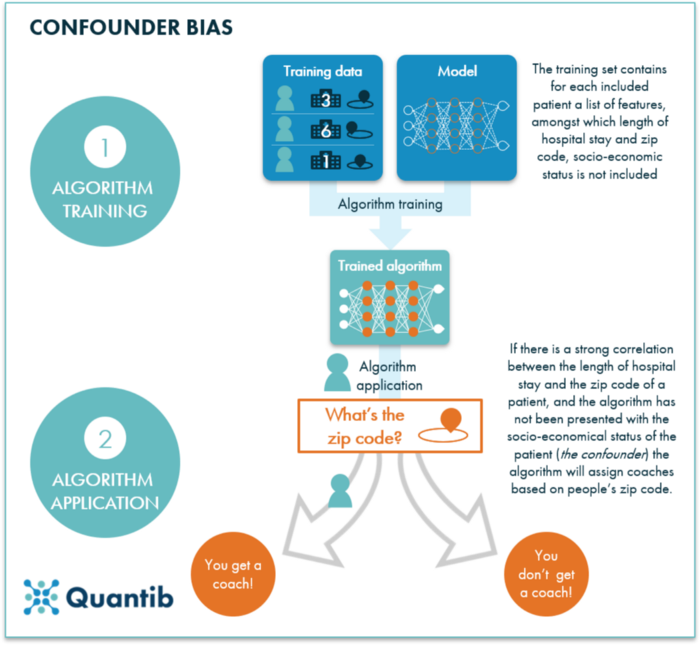
Figura 3: Um exemplo de viés de confusão: os dados de treinamento usados para este algoritmo contêm vários recursos por paciente, incluindo tempo de internação e código postal. O algoritmo final atribui uma correlação muito forte entre esses dois últimos recursos, o que resulta em uma saída dependendo fortemente do CEP, enquanto outro recurso, o status socioeconômico, não foi considerado e é o recurso que influencia tanto a duração da internação quanto o CEP . Esse recurso é chamado de fator de confusão.
O que podemos aprender com este exemplo de viés de IA na saúde?
Este é um caso específico em que o fator de confusão não é claro. Um fator de confusão é um recurso diferente que influencia os dois recursos que você pensava estarem conectados. Portanto, em vez de o tempo de internação hospitalar (recurso 1) ser influenciado pelo código postal (recurso 2), tanto o tempo de internação hospitalar quanto o CEP foram provavelmente influenciados pelo status socioeconômico (o fator de confusão).
Um momento de viés de IA na contemplação da saúde
Todos os três exemplos de viés de IA em saúde discutidos neste artigo mostram como um viés pode ser enraizado em um algoritmo, seja por não selecionar os assuntos certos para um conjunto de dados ou por ter escolhido os recursos errados para o algoritmo a ser treinado . No entanto, devemos estar cientes de que também existem muitas situações em que as decisões são afetadas por vieses introduzidos pelos próprios médicos ou pela interação dos médicos com um algoritmo.
Pode ficar claro que o viés da IA na área da saúde continua sendo um desafio, mas com a seleção de dados e design de algoritmo certos, esse desafio não é impossível de superar. Enquanto estamos nisso, devemos também pensar com muito cuidado sobre o que queremos que o algoritmo faça.
Não estamos implementando nossa própria maneira de pensar enquanto a IA oferece a oportunidade de criar maneiras mais objetivas de julgar do que a mente humana pode? Podemos selecionar os dados e treinar o algoritmo de forma que realmente eliminemos os preconceitos que o pensamento humano introduziria? O algoritmo de recrutamento da Amazon é um exemplo interessante.
Dizemos que os desenvolvedores falharam porque o algoritmo copiou o comportamento humano, mas mostra como podemos sonhar com um algoritmo que toma uma decisão mais justa do que nós.